

In the Atlassian’s playbook, it states that Sprint Retrospective’s goal is to identify how to improve teamwork by reflecting on what worked, what didn’t, and why. Usually, the meeting consists of brainstorming what the team did well and what the team needs to do better.
During my journey, I’ve been in many of these meetings, sometimes participating, sometimes facilitating. I’ve noticed that writing down post-its is painful for some people. When everybody is speaking, engineers get stuck and can’t think of anything else during the meeting.
Then, right after the meeting is over, many situations and problems emerge. They would like to discuss those topics. However, they wait a couple of weeks for the next meeting. Rarely they remember the issue. I don’t think the meeting gets as effective as it could.
To increase effectiveness, I think managers should promote a culture in which people raise their hands when the problems occur. They should discuss as soon and fresh in their mind as possible.
If the issue needs a more extended discussion, the team can add it to Evernote, Notion, GitHub Gist, or any other shareable document. A couple of sentences telling the problem with a little context would do the job.
The team can do the same as what did well. More post-its may pop up during the meeting. Then, the Scrum Master or facilitator can read the document.
When the meeting starts, the team already has a list of essential items to discuss. It saves time and makes it more productive.
So, how can teams make Sprint Retrospective meetings even more effective?
Using Pull Request Lead Time & Throughput in Sprint Retrospectives
I’ve been talking about Pull Request Lead Time and Throughput for a while. If you’re familiar with the term Cycle Time, I recommend reading my article on why I rather use Lead Time instead of Cycle Time.
To be explicit, in this article, Pull Request Lead Time measures how many days a Pull Request takes to be merged, and Throughput is the number of merged Pull Requests.
These two metrics can truly help teams to understand how they are performing. Besides, teams benefit from them when they look for the variability along the weeks. The data bring valuable insights and allow teams to question their decisions.
Let me explain through an example.
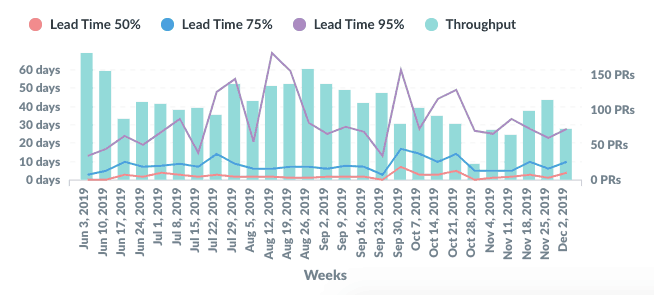
I took this chart as an example. Let’s say we’re back in January 2020. We’ve started the Sprint Retrospective creating post-its for the team’s issues and appraisals during the last weeks of December 2019.
We’ve discussed a bit, and now someone shares the chart above to analyze the Pull Request Lead Time and Throughput.
If the sprint is two-weeks long, we could use the metrics to ask ourselves questions like this:
- Why did we merge less Pull Requests in the week of Dec 2nd compared to Nov 25th?
- What did we do in the week of Nov 25th that allowed us to merge more Pull Requests than the last few Sprints?
- Why did the Lead Time increase in the week of Dec 2nd?
Asking this kind of question is fundamental. However, nobody should point fingers or blame other people. That’s not healthy nor effective.
I would expect answers like this:
- We merged less Pull Requests in the last week because we had a massive refactoring going on.
- In the Week of Nov 25th, we fixed several small bug fixes that popped up after deploying a problematic feature in the week before.
- The Lead Time increased because everyone held their reviews, and we made a task force to merge the refactoring.
The numbers themselves don’t matter as much as the story behind them. Now it’s time to ask what are learnings from the last iteration. Here are some alternatives to address those issues:
- Should we avoid massive refactorings because they slow down everyone? Should we make it part of the team’s guidelines?
- Deploying complex features may lead to a higher escaped bugs rate. How to minimize the impact? Should we invest more effort into testing? Should we deliver smaller changes? Should we adopt a more incremental approach? Should we consider a gradual rollout?
- Was the task force an effective strategy? Maybe fewer people working on the refactoring at the same time ships it faster.
As you can see, the data allow teams to derive relevant aspects for the Retrospective. The discussion is a tremendous source of knowledge and should generate insights for improving the development flow.
In short
Sprint Retrospectives can be more effective using metrics. The team can extract valuable knowledge by questioning the Pull Request Lead Time and Throughput. Indeed, other metrics are useful, as well.
The crucial point is to use the metrics to distill tacit knowledge and formalize it. What went well and what went wrong should promote changes in the process, feed guidelines, and motivate new practices.
That’s what an effective Sprint Retrospective is about, in my opinion.

Originally published at https://sourcelevel.io on September 4, 2020.


